Model Performance Evaluation
Why evaluate?
Evaluation makes routing data-driven. By measuring per-category accuracy on MMLU-Pro (and doing a quick sanity check with ARC), you can:
- Select the right model for each category and rank them into categories.model_scores
- Pick a sensible default_model based on overall performance
- Decide when CoT prompting is worth the latency/cost tradeoff
- Catch regressions when models, prompts, or parameters change
- Keep changes reproducible and auditable for CI and releases
In short, evaluation converts anecdotes into measurable signals that improve quality, cost efficiency, and reliability of the router.
This guide documents the automated workflow to evaluate models (MMLU-Pro and ARC Challenge) via a vLLM-compatible OpenAI endpoint, generate a performance-based routing config, and update categories.model_scores in config.
see code in /src/training/model_eval
What you'll run end-to-end
1) Evaluate models
- per-category accuracies
- ARC Challenge: overall accuracy
2) Visualize results
- bar/heatmap plot of per-category accuracies
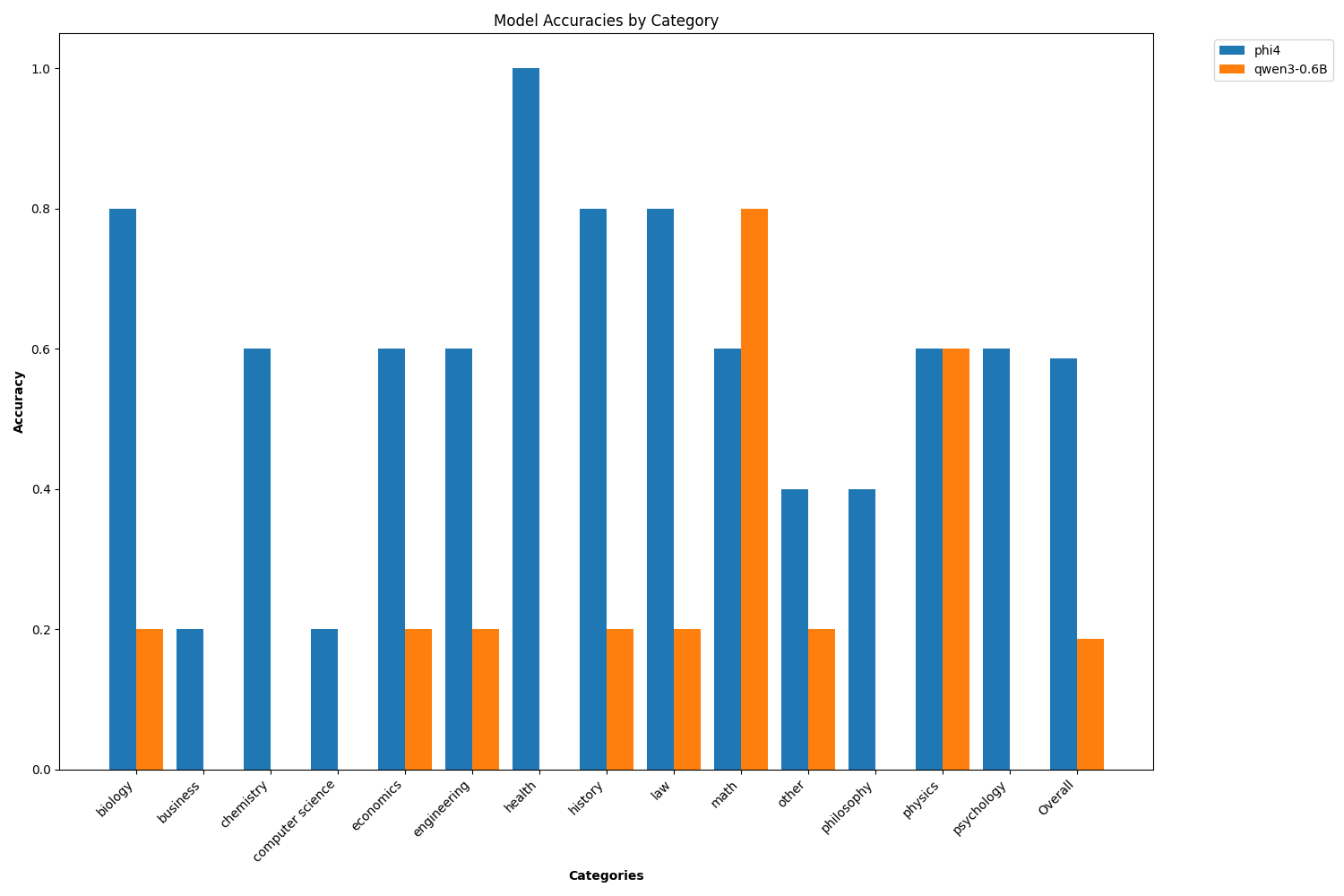
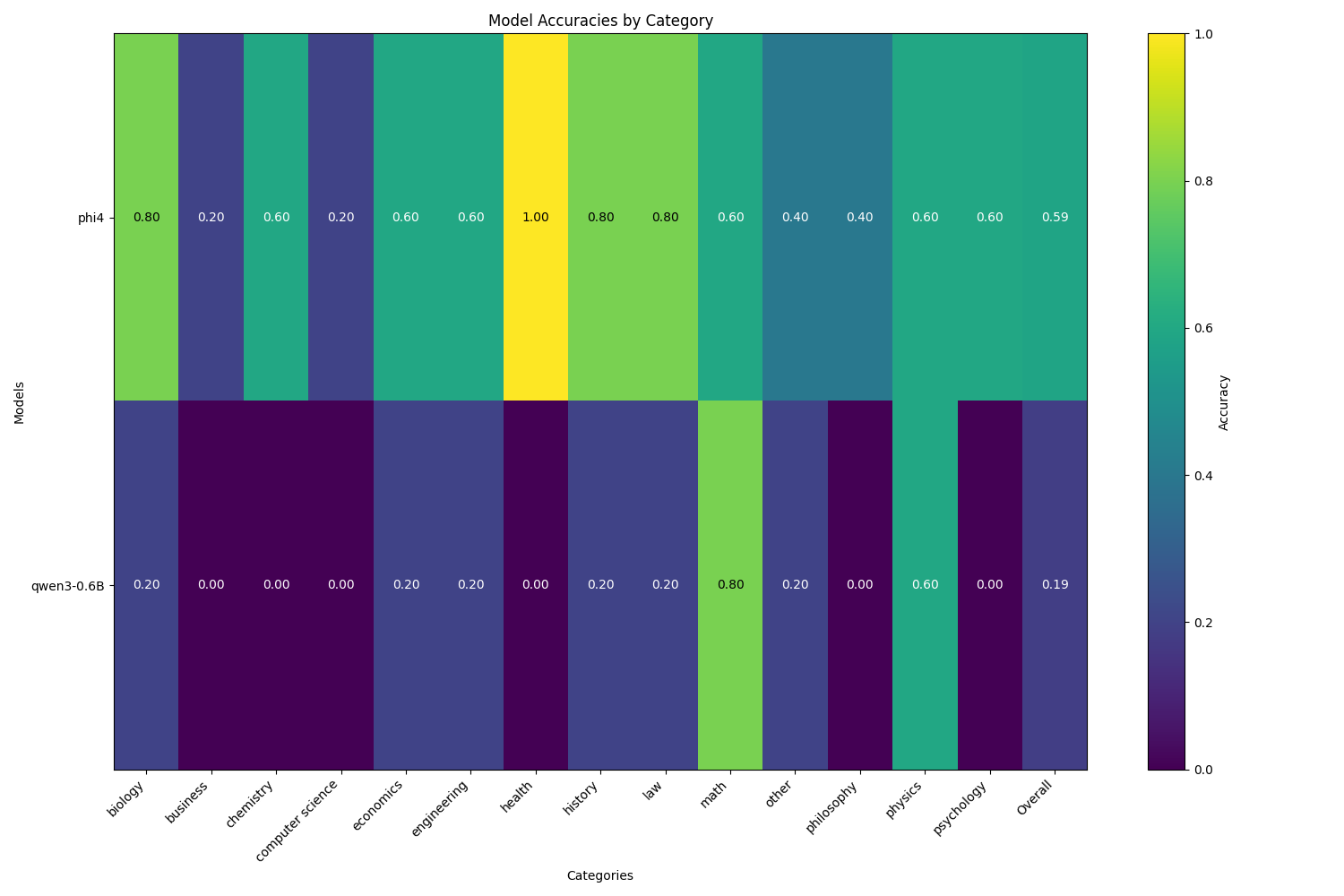
3) Generate an updated config.yaml
- Rank models per category into categories.model_scores
- Set default_model to the best average performer
- Keep or apply category-level reasioning settings
1.Prerequisites
-
A running vLLM-compatible OpenAI endpoint serving your models
- Endpoint URL like http://localhost:8000/v1
- Optional API key if your endpoint requires one
# Terminal 1
vllm serve microsoft/phi-4 --port 11434 --served_model_name phi4
# Terminal 2
vllm serve Qwen/Qwen3-0.6B --port 11435 --served_model_name qwen3-0.6B -
Python packages for evaluation scripts:
- From the repo root: matplotlib in requirements.txt
- From
/src/training/model_eval: requirements.txt
# We will work at this dir in this guide
cd /src/training/model_eval
pip install -r requirements.txt
Optional tip:
- Ensure your
config/config.yamlincludes your deployed model names undervllm_endpoints[].modelsand any pricing/policy undermodel_configif you plan to use the generated config directly.
2.Evaluate on MMLU-Pro
see script in mmul_pro_vllm_eval.py
Example usage patterns
# Evaluate a few models, few samples per category, direct prompting
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:11434/v1 \
--models phi4 \
--samples-per-category 10
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:11435/v1 \
--models qwen3-0.6B \
--samples-per-category 10
# Evaluate with CoT (results saved under *_cot)
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:11435/v1 \
--models qwen3-0.6B \
--samples-per-category 10
--use-cot
# If you have set up Semantic Router properly, you can run in one go
python mmlu_pro_vllm_eval.py \
--endpoint http://localhost:8801/v1 \
--models qwen3-0.6B, phi4 \
--samples-per-category
# --use-cot # Uncomment this line if use CoT
Key flags
- --endpoint: vLLM OpenAI URL (default http://localhost:8000/v1)
- --models: space-separated list OR a single comma-separated string; if omitted, the script queries /models from the endpoint
- --categories: restrict evaluation to specific categories; if omitted, uses all categories in the dataset
- --samples-per-category: limit questions per category (useful for quick runs)
- --use-cot: enables Chain-of-Thought prompting variant; results are saved in a separate subfolder suffix (_cot vs _direct)
- --concurrent-requests: concurrency for throughput
- --output-dir: where results are saved (default results)
- --max-tokens, --temperature, --seed: generation and reproducibility knobs
What it outputs per model
- results/Model_Name_(direct|cot)/
- detailed_results.csv: one row per question with is_correct and category
- analysis.json: overall_accuracy, category_accuracy map, avg_response_time, counts
- summary.json: condensed metrics
- mmlu_pro_vllm_eval.txt: prompts and answers log (debug/inspection)
Note
- Model naming: slashes are replaced with underscores for folder names; e.g., gemma3:27b -> gemma3:27b_direct directory.
- Category accuracy is computed on successful queries only; failed requests are excluded.
3.Evaluate on ARC Challenge (optional, overall sanity check)
see script in arc_challenge_vllm_eval.py
Example usage patterns
python arc_challenge_vllm_eval.py \
--endpoint http://localhost:8801/v1\
--models qwen3-0.6B,phi4
--output-dir arc_results
Key flags
- --samples: total questions to sample (default 20); ARC is not categorized in our script
- Other flags mirror the MMLU-Pro script
What it outputs per model
- results/Model_Name_(direct|cot)/
- detailed_results.csv: one row per question with is_correct and category
- analysis.json: overall_accuracy, avg_response_time
- summary.json: condensed metrics
- arc_challenge_vllm_eval.txt: prompts and answers log (debug/inspection)
Note
- ARC results do not feed
categories[].model_scoresdirectly, but they can help spot regressions.
4.Visualize per-category performance
see script in plot_category_accuracies.py
Example usage patterns:
# Use results/ to generate bar plot
python plot_category_accuracies.py \
--results-dir results \
--plot-type bar \
--output-file results/bar.png
# Use results/ to generate heatmap plot
python plot_category_accuracies.py \
--results-dir results \
--plot-type heatmap \
--output-file results/heatmap.png
# Use sample-data to generate example plot
python src/training/model_eval/plot_category_accuracies.py \
--sample-data \
--plot-type heatmap \
--output-file results/category_accuracies.png
Key flags
- --results-dir: where analysis.json files are
- --plot-type: bar or heatmap
- --output-file: output image path (default model_eval/category_accuracies.png)
- --sample-data: if no results exist, generates fake data to preview the plot
What it does
- Finds all
results/**/analysis.json, aggregates analysis["category_accuracy"] per model - Adds an Overall column representing the average across categories
- Produces a figure to quickly compare model/category performance
Note
- It merges
directandcotas distinct model variants by appending:director:cotto the label; the legend hides:directfor brevity.
5.Generate performance-based routing config
see script in result_to_config.py
Example usage patterns
# Use results/ to generate a new config file (not overridden)
python src/training/model_eval/result_to_config.py \
--results-dir results \
--output-file config/config.eval.yaml
# Modify similarity-thredshold
python src/training/model_eval/result_to_config.py \
--results-dir results \
--output-file config/config.eval.yaml \
--similarity-threshold 0.85
# Generate from specific folder
python src/training/model_eval/result_to_config.py \
--results-dir results/mmlu_run_2025_09_10 \
--output-file config/config.eval.yaml
Key flags
- --results-dir: points to the folder where analysis.json files live
- --output-file: target config path (default config/config.yaml)
- --similarity-threshold: semantic cache threshold to set in the generated config
What it does
- Reads all
analysis.jsonfiles, extracting analysis["category_accuracy"] - Constructs a new config:
- categories: For each category present in results, ranks models by accuracy:
- category.model_scores =
[{ model: "Model_Name", score: 0.87 }, ...], highest first
- category.model_scores =
- default_model: the best average performer across categories
- category reasoning settings: auto-filled from a built-in mapping (you can adjust after generation)
- math, physics, chemistry, CS, engineering -> high reasoning
- others default -> low/medium
- Leaves out any special “auto” placeholder models if present
- categories: For each category present in results, ranks models by accuracy:
Schema alignment
- categories[].name: the MMLU-Pro category string
- categories[].model_scores: descending ranking by accuracy for that category
- default_model: a top performer across categories (approach suffix removed, e.g., gemma3:27b from gemma3:27b:direct)
- Keeps other config sections (semantic_cache, tools, classifier, prompt_guard) with reasonable defaults; you can edit them post-generation if your environment differs
Note
- This script only work with results from MMLU_Pro Evaluation.
- Existing config.yaml can be overwritten. Consider writing to a temp file first and diffing:
--output-file config/config.eval.yaml
- If your production config.yaml carries environment-specific settings (endpoints, pricing, policies), port the evaluated
categories[].model_scoresanddefault_modelback into your canonical config.
Example config.eval.yaml
see more about config at configuration
bert_model:
model_id: sentence-transformers/all-MiniLM-L12-v2
threshold: 0.6
use_cpu: true
semantic_cache:
enabled: true
similarity_threshold: 0.85
max_entries: 1000
ttl_seconds: 3600
tools:
enabled: true
top_k: 3
similarity_threshold: 0.2
tools_db_path: config/tools_db.json
fallback_to_empty: true
prompt_guard:
enabled: true
use_modernbert: true
model_id: models/jailbreak_classifier_modernbert-base_model
threshold: 0.7
use_cpu: true
jailbreak_mapping_path: models/jailbreak_classifier_modernbert-base_model/jailbreak_type_mapping.json
# Lack of endpoint config and model_config right here, modify here as needed
classifier:
category_model:
model_id: models/category_classifier_modernbert-base_model
use_modernbert: true
threshold: 0.6
use_cpu: true
category_mapping_path: models/category_classifier_modernbert-base_model/category_mapping.json
pii_model:
model_id: models/pii_classifier_modernbert-base_presidio_token_model
use_modernbert: true
threshold: 0.7
use_cpu: true
pii_mapping_path: models/pii_classifier_modernbert-base_presidio_token_model/pii_type_mapping.json
categories:
- name: business
use_reasoning: false
reasoning_description: Business content is typically conversational
reasoning_effort: low
model_scores:
- model: phi4
score: 0.2
- model: qwen3-0.6B
score: 0.0
- name: law
use_reasoning: false
reasoning_description: Legal content is typically explanatory
reasoning_effort: medium
model_scores:
- model: phi4
score: 0.8
- model: qwen3-0.6B
score: 0.2
# Ignore some categories here
- name: engineering
use_reasoning: true
reasoning_description: Engineering problems require systematic problem-solving
reasoning_effort: high
model_scores:
- model: phi4
score: 0.6
- model: qwen3-0.6B
score: 0.2
default_reasoning_effort: medium
default_model: phi4